

The Avatar method, designed for anonymizing tabular data, can be repurposed, without algorithmic modification, to selectively desensitize a specific category within a dataset.
Sharing data without exposing a sensitive category
Let's take an example from a defense context. Modern armies manage extremely diverse fleets of land vehicles: combat vehicles, command vehicles, light vehicles, transport vehicles, etc. To optimize predictive maintenance, inventory management, and operational planning, this data is regularly shared between departments, industrial subcontractors, and partners.
However, certain vehicle categories are inherently sensitive. This is the case, for example, for vehicles transporting classified equipment : their technical characteristics (mass, range, thermal and radar signatures) constitute sensitive and identifying information. A machine learning model trained on the complete repository could easily identify these vehicles, creating a major security flaw.
Challenge : how to share fleet data for routine logistical uses, while making it impossible to identify the sensitive category?
Desensitization and evaluation methodology
The Avatar method generates, for each individual in a dataset, a synthetic avatar calculated as the weighted barycenter of its k nearest neighbors in a projected space. Designed for anonymization, this mechanism can be exploited differently.
The principle : force the neighbors of each vehicle in the target class to come exclusively from other categories. The resulting avatar is then "pulled" towards the average characteristics of non-sensitive vehicles, making its classification much more difficult.
Data:
The dataset used is a technical repository of military land vehicles comprising 16 measured characteristics (mass, dimensions, range, signatures…) and 7 vehicle categories.
Note: For confidentiality reasons, the data presented here comes from a public dataset (Dry Bean — UCI) whose variables and classes have been renamed to fit the theme. The numerical values are strictly identical: the distributions, correlations, and statistical structures are those of the real dataset. This methodological choice does not diminish the validity of the analysis in any way; only the labels are fictitious, the statistical demonstration remains rigorous.
Evaluation Protocol Steps:
- Stratified 70/30 split: The dataset (2,000 rows) is split into training (1,400) and test (600) sets, with the test set remaining unchanged for both models.
- Generation of the desensitized dataset: A set of avatars (1400*) is generated from the training set (1,400) with the particularity that the neighbors used during generation cannot belong to the target class to be desensitized (vehicles transporting classified material)
- Comparison: An XGBoost prediction algorithm with isoparameters is trained on the original training data (1,400) and on the desensitized training data (1,400*) respectively. They are then evaluated and compared on the unchanged test set (600) derived from the original data.
Results
A classifier (XGBoost) is trained before and after desensitization on the same test data.
Key metrics:
- Overall Accuracy: The classification model's overall ability to predict the vehicle's class based on its information remains unchanged 91% → 91%.
- Precision classified material : However, the model's specific ability to predict that a vehicle belongs to the sensitive class classified material drops by 30 points with desensitized data 92% → 62%.
- The model's specific predictive performance on other categories is barely impacted.
The model retains its overall performance. The data remains perfectly useful for logistics, but significantly loses its ability to identify vehicles carrying classified material.
Additional analyses:
Analysis of the confusion matrices from both models (raw training data, desensitized training data) allows us to observe the reallocation of predictions.

The row corresponding to the target class (classified material) shows a clear evolution. After desensitization, classification errors increase sharply for this category, proving that the model struggles to isolate it by increasing confusion between the classes combat vehicles and engineering vehicles.
To complement this analysis, we compare the specific prediction performance of the two models by vehicle class (raw training data, desensitized training data).
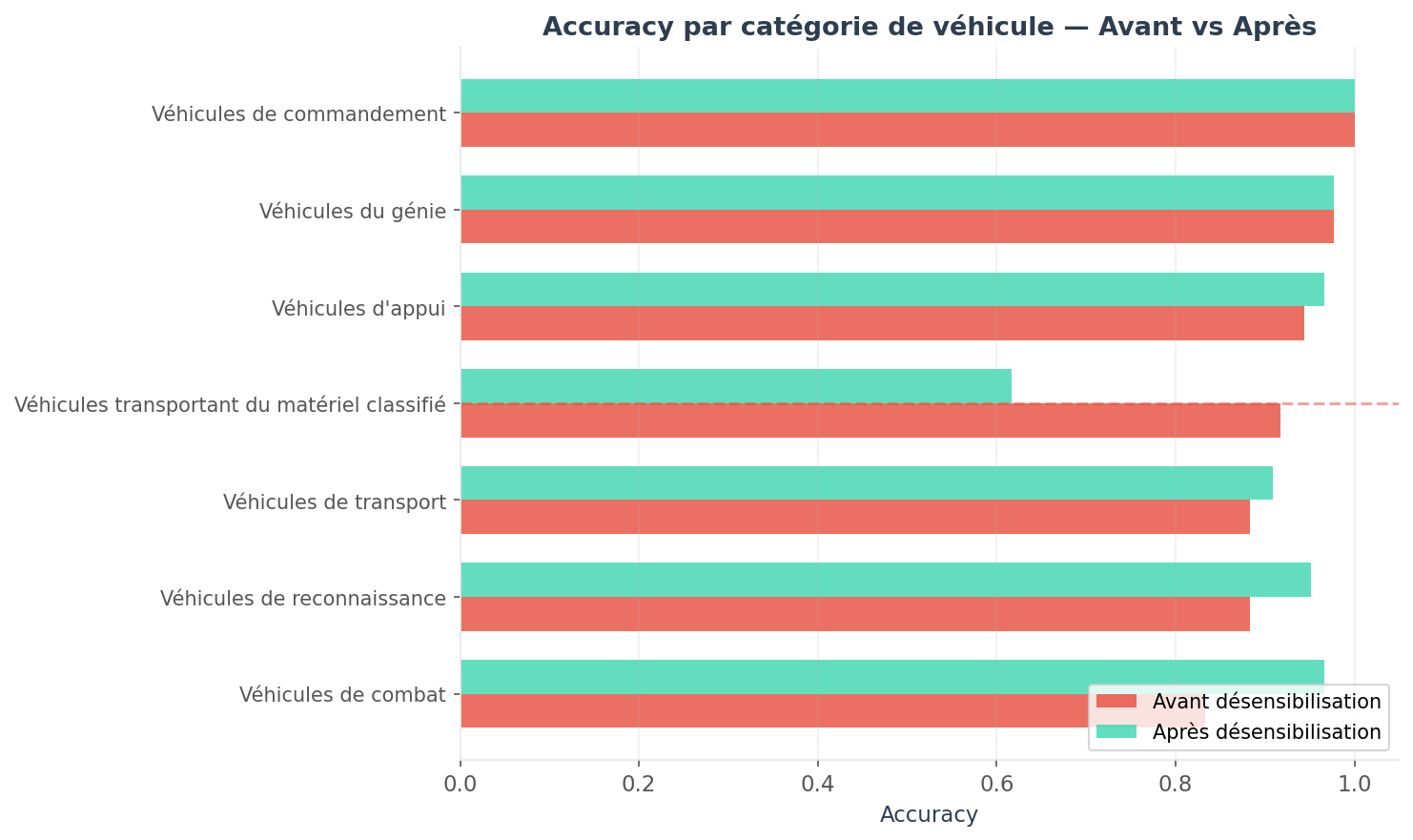
The method's impact is precisely focused on the target class. Other categories maintain stable and reliable prediction performance for operations.
Once the prediction models have been compared, a more precise analysis of the prediction variables can be performed. Analyzing the importance of variables in predicting the target class with raw (non-desensitized) data allows for profiling the target class before desensitization.

SHAP values reveal which features enable the model to identify vehicles carrying classified material. In our example, vehicle width is the primary information allowing the model to discriminate data as originating from this sensitive class.
Once the main discriminating variable has been identified, we can compare the distributions of the width variable between raw and desensitized data.
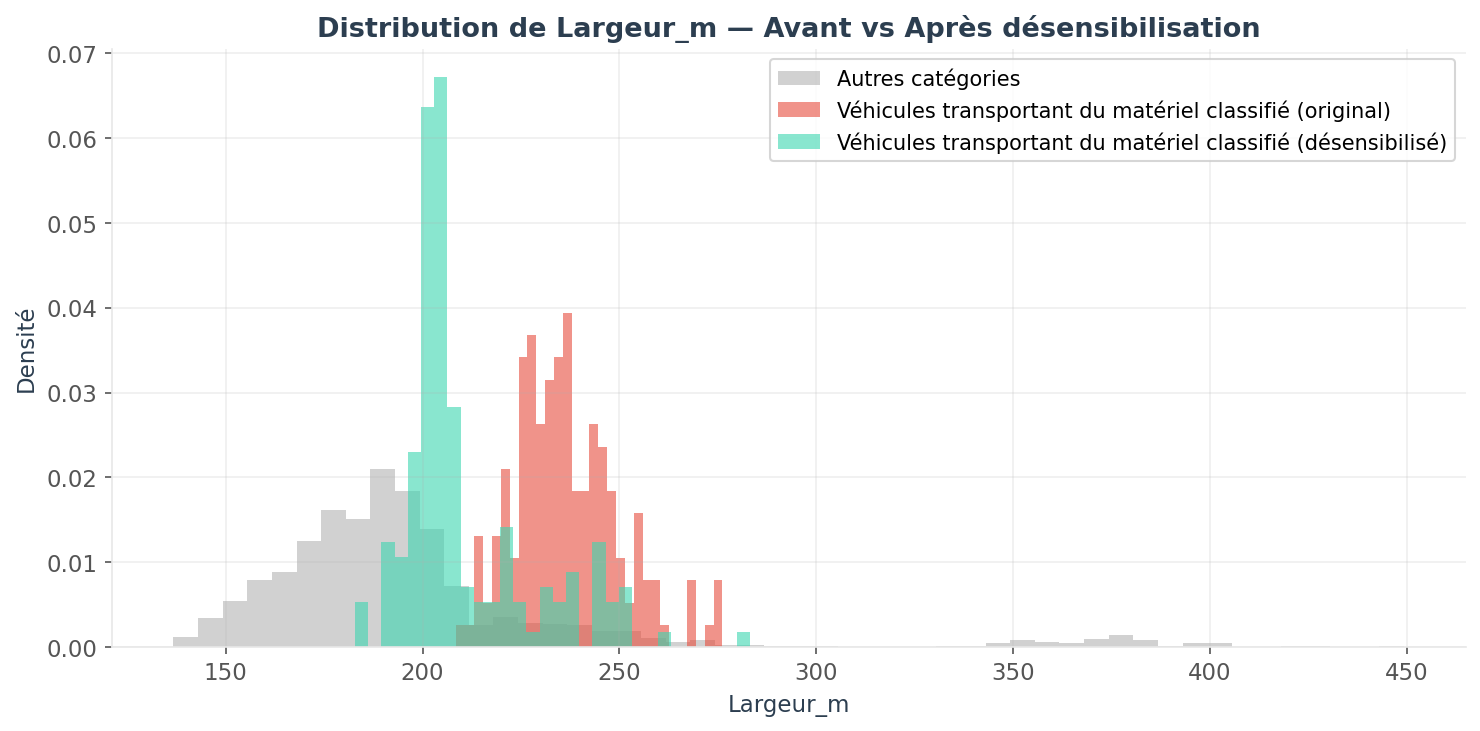
The most discriminating variable sees its distribution for the target class vehicles carrying classified material significantly approach that of other categories, making purely statistical distinction more difficult.
Finally, to complete the analysis, a multi-modal analysis of the target class's singularity in a projection space is performed.

An unsupervised Principal Component Analysis (PCA) allows for visualizing this shift in the data space. Before the operation, vehicles carrying classified material form an identifiable and isolated cluster. After desensitization, these same data points disperse and blend into the areas of the space occupied by other vehicle categories.
Robustness check
A potential risk inherent in these methods is that desensitized data could form a new cluster recognizable artificial cluster. However, neighborhood analysis (KNN algorithm with k=10) shows that the proportion of neighbors from the same class decreases from ~56% to ~17% — meaning the data points effectively blend with other categories organically, without creating a new signal exploitable by an attacker.
Key considerations
- Isolated target class: The approach works better when the target class is initially well distinguishable from other categories.
- Internal correlations: The original correlations within the target class are mechanically altered by the procedure.
- Parameter k: Using a larger k strengthens desensitization but proportionally increases the loss of fine data structure.
- Reproducibility: The process remains deterministic (by using a fixed seed) and perfectly auditable by trusted third parties.
Conclusion
The Avatar method, used here without any modification to its fundamental algorithms, significantly reduces a learning model's ability to identify a particularly sensitive category, while preserving overall performance on the rest of the dataset.
In practice, this ensures that critical logistics data can be securely shared between government agencies, armed forces, or industrial partners for routine MCO (maintenance in operational condition) uses — while ensuring that a third party (legitimate or malicious) will not be able to isolate vehicles transporting classified material from this data.
This innovative approach directly paves the way for a selective desensitization feature that can be natively integrated into data privacy software platforms. It is transferable to any context (health, finance, telecoms) where a very specific category needs to be made "stealthy" within a large, shared dataset.
Links
Avatar method technical documentation
Contact



