

We reproduced the most aggressive linking attack described in academic literature and applied it to avatars. Result: under realistic conditions, the risk of re-identification remains negligible. This article details the methodology, results, and positions our own evaluation metric (Hidden Rate) against these academic standards, all contextualized within a Data Protection Impact Assessment (DPIA).
The linking attack
Linking can be likened to the individualization criterion defined by the European Data Protection Board (EDPB) for assessing the anonymization of a dataset, alongside correlation and inference.
Definition. A linking attack consists of connecting a synthetic record (or a group of records) to a real individual. If this association is possible, anonymization is compromised.
In the context of synthetic data, the question becomes: can an attacker, by exploiting one or more published avatar datasets, reconstruct a link to individuals in the source dataset?
We test two variants:
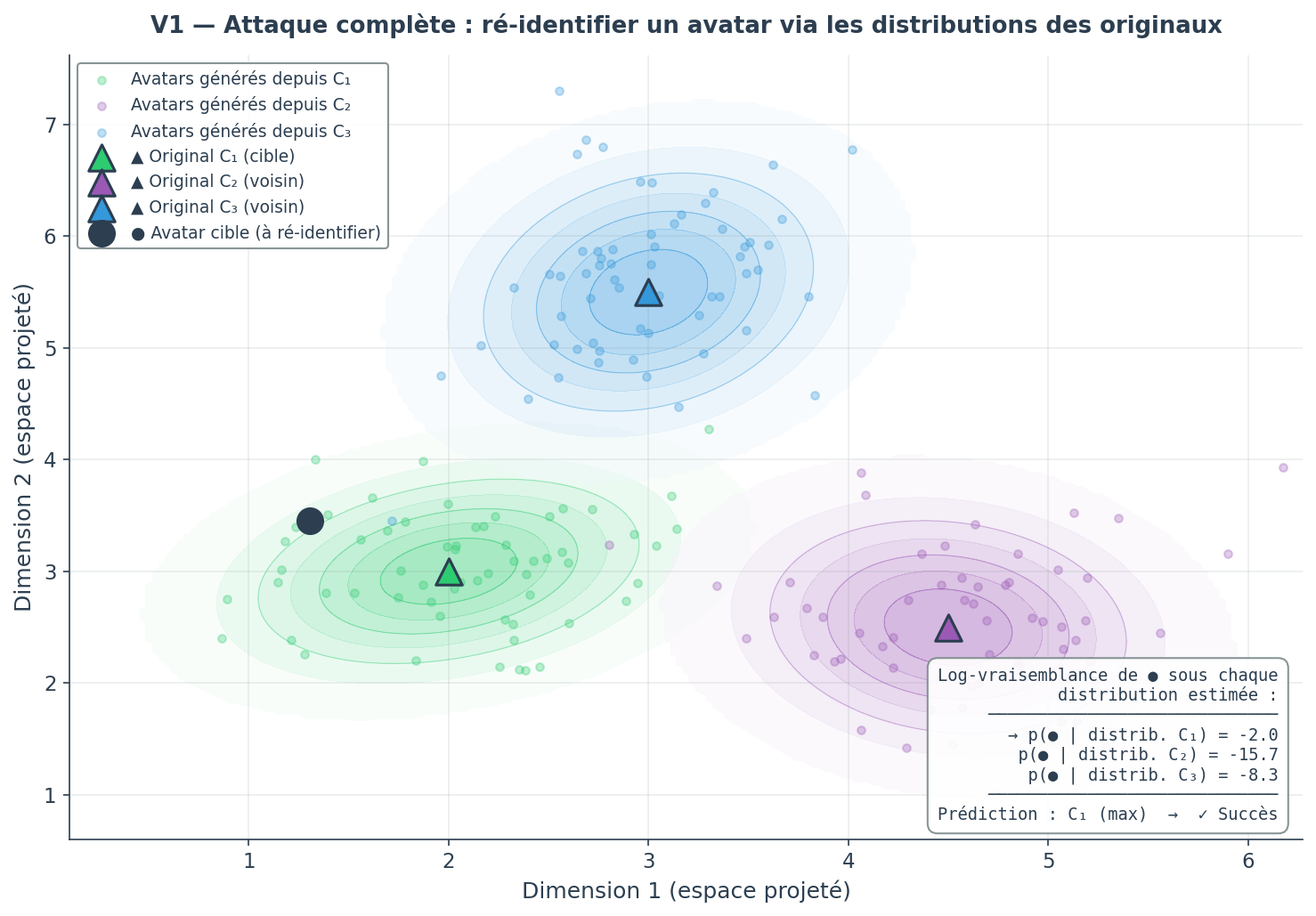
- V1 (full attack): the attacker has access to the original data as well as t avatar datasets. Unrealistic theoretical scenario.
- V2 (restricted attack): the attacker only has access to published avatars as well as a t second-generation avatar dataset. More realistic theoretical scenario.
Reproduction protocol
The attack consists of five steps:
- Data generation:
V1 : we start from an original dataset (AIDS – 2,139 individuals, 24 mixed variables) from which we produce t = 100 generations of avatars with the parameter k = 5.
V2 : we start from a dataset of avatars derived from the originals (first-generation avatars) to produce t = 100 generations of avatars derived from avatars (second-generation avatars) with the parameter k = 5.
- Projection into a shared latent space.
The entire dataset (originals and 100 avatars for V1 – first-generation avatars, and 100 second-generation avatars for V2) is projected into a reduced-dimension subspace via a Multiple Factor Analysis (MFA).
- Estimation of individual distributions.
V1 : For each individual i from the original set, the attacker uses their 100 avatars to estimate a distribution in space as a multivariate Gaussian.
V2 : For each first-generation avatar, the attacker uses their 100 second-generation avatars to estimate a distribution in space as a multivariate Gaussian.
- Restriction to the 50 nearest neighbors.
For each target avatar to be re-identified, the attacker restricts candidates to the 50 individuals whose estimated mean is the closest (Euclidean distance).
- Maximum likelihood assignment.
Among these 50 candidates, the attacker identifies the one that maximizes the log-likelihood under the estimated distribution. In V1, they evaluate each target avatar under the distributions of neighboring originals. In V2, they evaluate each first-generation avatar under its own distribution of second-generation avatars.
The final re-identification rate is calculated as the proportion of avatars correctly assigned to their source individual. In V1, a success means the avatar is attributed to the correct original. In V2, a success means that the first-generation avatar is the most likely point under its own distribution. In other words, it is statistically distinguishable from its neighbors. This singularization is the necessary condition for re-identification: if the attacker cannot distinguish an avatar from its neighbors, they cannot confirm a link to a real individual, even with auxiliary information.

Results
Summary table

Interpreting the results
V1 (full attack):
For this dataset, with k=5 and 100 generations, the attacker who knows the originals manages to re-identify 87% of individuals. This figure might seem alarming in isolation. However, it relies on an unrealistic assumption: the attacker already possesses the personal data they are trying to re-identify. If the adversary already knows the data, re-identification provides no additional information.
V2 (restricted attack):
In the realistic scenario, the attacker only manages to single out 2.6% of the avatars for k=5, a result barely better than random chance (2% = 1/50 candidates). In practice, for 97.4% of the avatars, the distribution estimated via avatar-of-avatar does not allow them to be distinguished from their neighbors: the statistical signatures are indistinguishable. If the attacker cannot even identify which avatar is which in the published dataset, they are a fortiori incapable of tracing back to the original individual.
Comparison to the Hidden Rate :
The Hidden Rate is a standard Octopize metric for evaluating resistance to chaining: it measures the proportion of original individuals whose closest avatar is not their own. It is a metric static and geometric, calculated based on a single generation of avatars. Conversely, V1 and V2 are statistical and dynamic attacks that attempt to exploit data accumulation across multiple generations (T=100).
At k=5, 18.5% of individuals are considered re-identifiable by chaining.
Contextualization
In accordance with the approach described in our article on [the pragmatic approach to anonymization], it is essential not to interpret raw metrics out of context. The measurements show that:
- Under conditions ideal for the attacker (V1), a theoretical risk exists.
- Under realistic conditions (V2), the risk is statistically negligible for k=5.
- Octopize's chaining metric (Hidden Rate) lies between these two scenarios. It is a cautious compromise indicator: it deliberately overestimates the risk compared to a realistic V2 attack to ensure a safety margin, while remaining more realistic than the V1 scenario.
For the V1 attack to be feasible, an adversary would need to have the complete original dataset, access to 100 independent avatar sets, master advanced statistical estimation, and know that these avatars come from the same dataset. In practice, if a user publishes only one avatar set (the standard case), the V1 attack is unfeasible. Furthermore, if the attacker has no means of generating new avatars, the V2 attack also becomes unfeasible.
Impact of the number of simulations on attack performance
Although the V1 attack is unrealistic in practice, it raises an interesting question. How does the risk evolve based on the number of available avatar generations?
Indeed, access to 100 avatar iterations from an original dataset is a strong assumption, but access to 2, 3, or even 10 versions is not improbable, especially in the context of using the method for data augmentation.
We therefore measured the evolution of the re-identification rate as a function of the augmentation factor, for k=5:

V1 (full attack):
rapidly progresses up to x20 (~83%), then saturates around 87%. Beyond x35, the marginal gain is almost zero — the Gaussian distribution is already well estimated with about thirty points.
V2 (restricted attack):
remains stable between 1% and 2.6% regardless of the amplification factor. The approximation by avatars of avatars does not converge towards the real distributions, even with 50 generations.
Even when publishing a dataset amplified x100, the risk under realistic conditions (V2) remains in the negligible risk zone (<5%). Data augmentation using avatars remains a safe practice from a privacy perspective.
Conclusion
- Robustness under realistic conditions. The V2 attack consistently fails. The avatar generation process does not retain enough individual traces for an attacker without access to the originals to reconstruct a link.
- Consistency with the regulatory framework. The GDPR evaluates anonymization in terms of 'reasonable means'. The V1 attack requires unreasonable means (prior access to personal data); the V2 attack, which is the only reasonable one, does not produce significant re-identification.
- Transparency of the approach. In accordance with our commitment to transparency, we are publishing this analysis, including the results of V1 — not because they represent a real risk, but because they illustrate the methodology and its theoretical limits.
Links
- Documentation of privacy metrics
- Article: Pragmatic Approach to Anonymization (DPIA)
- Article: Understanding Membership Inference Attacks
- Contact



