
Our scientific publications


March 10, 2023
Génération de données synthétiques centrées sur le patient, aucune raison de risquer la réidentification dans l'analyse des données biomédicales
Ce papier présente la méthode Avatar d’Octopize. La méthode Avatar génère des données synthétiques qui conservent toute la richesse statistique des données réelles, tout en garantissant la confidentialité des individus.Conçue selon les critères du Comité européen de la protection des données, elle offre une approche centrée sur le patient et une anonymisation robuste, sans compromis entre utilité et protection.

August 25, 2021
Application d'une nouvelle méthode d'anonymisation des données d'électrocardiogramme (Chronos)
Cet article présente Chronos : une méthode d’anonymisation dédiée aux données temporelles, testée sur des signaux ECG.Elle génère des données synthétiques fidèles aux originales, avec seulement 3 % de différence de précision sur les modèles entraînés.Une approche qui protège les individus tout en préservant la qualité scientifique des données.
March 4, 2025
Leveraging patients’ longitudinal data to improve the Hospital One-year Mortality Risk
This study introduces ELSTM, a neural network that analyzes patients' complete histories to more accurately predict their risk of mortality at one year after admission. To promote research while maintaining confidentiality, the authors have also published a synthetic data set reproducing the real characteristics of patients.
Genetic architecture of Multiple Sclerosis patients in the French national OFSEP-HD cohort
This article presents the genetic analysis of the OFSEP-HD cohort, comprising more than 2,600 patients with multiple sclerosis followed over five years. The study highlights the genetic diversity of patients and the limits of original self-declarations, while proposing the creation of a synthetic and anonymous genetic data set to promote sharing and open research.
June 24, 2025
Privacy-by-design generation of two virtual clinical trials in multiple sclerosis and their release as open datasets
This article discusses the use of the Avatar method to generate synthetic randomized clinical trials using real data from patients with multiple sclerosis. The results show that this approach makes it possible to accurately reproduce clinical analyses while guaranteeing robust confidentiality, even in the face of the most complex inference attacks. Two sets of anonymous and open placebo data have thus been published to demonstrate the potential of the secure sharing of health data.
July 31, 2024
Application of blinded synthetic data: the case of data from the CONSTANCES cohort
This article presents a large-scale scientific validation of the Octopize Avatar method, applied to the CONSTANCES cohort (more than 160,000 individuals). The results show that the synthetic data faithfully reproduce the statistical associations of real data, with minimal differences and a high degree of agreement between the results. This study confirms that avatar data offers a reliable and GDPR-compliant alternative for sharing and exploiting massive data safely.
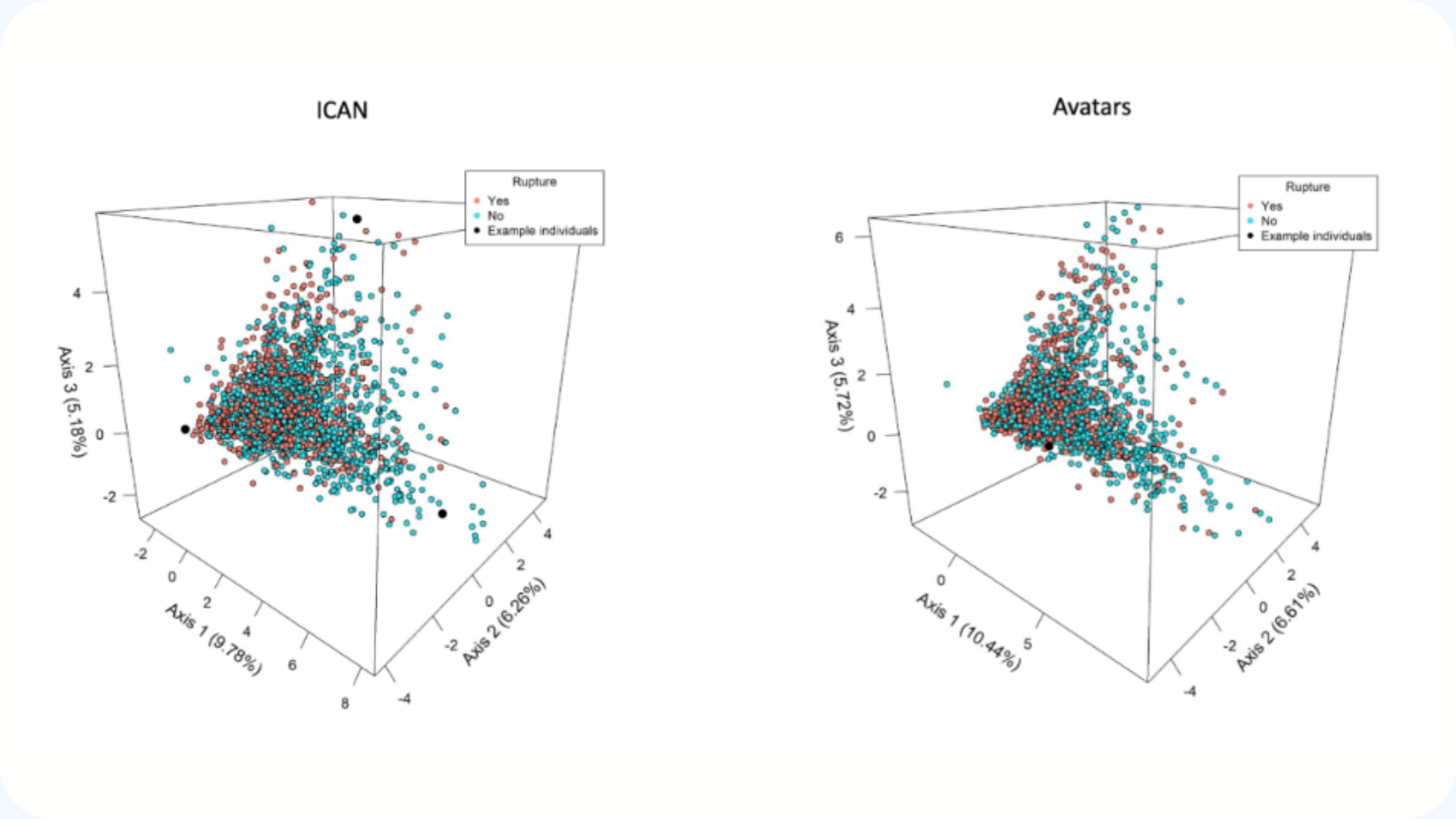
October 23, 2020
Location of intracranial aneurysms is the main factor associated with rupture in the ICAN population
This article presents the French ICAN project, a national program aimed at better understanding the mechanisms of formation and rupture of intracranial aneurysms. By combining high-throughput genetic analyses, imaging and clinical data, the project seeks to identify new genes and biomarkers that are predictive of aneurysm risk. This work paves the way for the development of new diagnostic and therapeutic tools for better prevention of aneurysms.
April 5, 2023
Pedagogical notebook on the uses of synthetic data
This article presents the collaboration between Octopize and the Health Data Hub around an educational notebook dedicated to the generation and evaluation of synthetic health data. This work compares several approaches to measure both the quality and the level of anonymity of the data produced. The Octopize method is distinguished by its ability to guarantee confidentiality while maintaining scientific reproducibility, regardless of the use case.
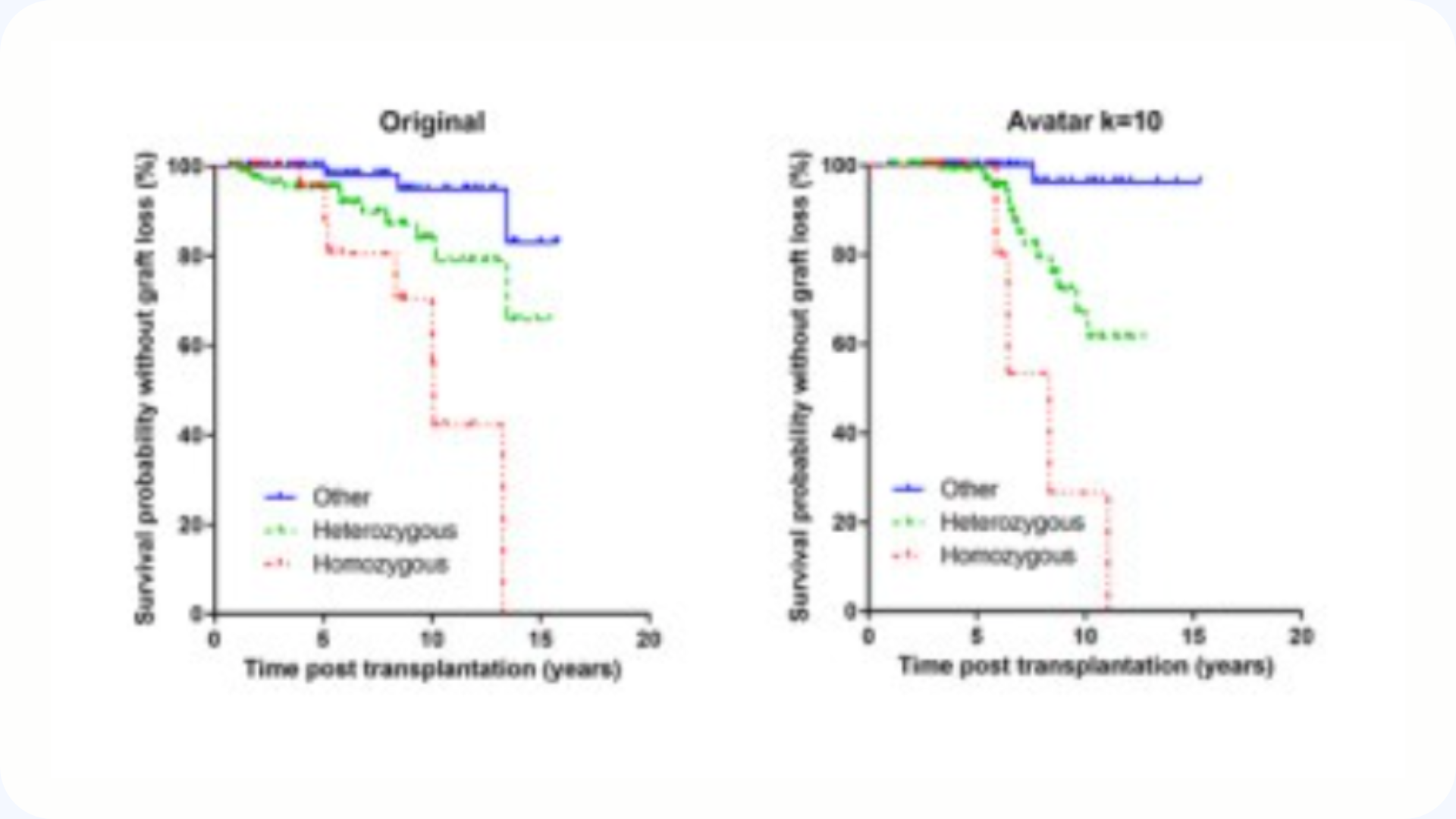
October 16, 2024
To be or not to be, when synthetic data meets clinical pharmacology: a study focused on pharmacogenetics
This article compares three synthetic data generation methods — CT-GAN, TVAE, and Avatar — applied to a set of pharmacogenetic data. The results show that Avatar (k = 10) and CT-GAN offer the best balance between data usefulness and privacy, with estimates close to real data. This study highlights the potential of synthetic data for pharmacological research, while identifying ways to optimize small data sets.

March 10, 2023
Patient-centric synthetic data generation, no reason to risk re-identification in the analysis of biomedical pseudonymized data
Octopize's Avatar method generates synthetic data that maintains all the statistical richness of real data, while guaranteeing the confidentiality of individuals. Designed according to the criteria of the European Data Protection Board, it offers a patient-centered approach and robust anonymization, without compromising between usefulness and protection.
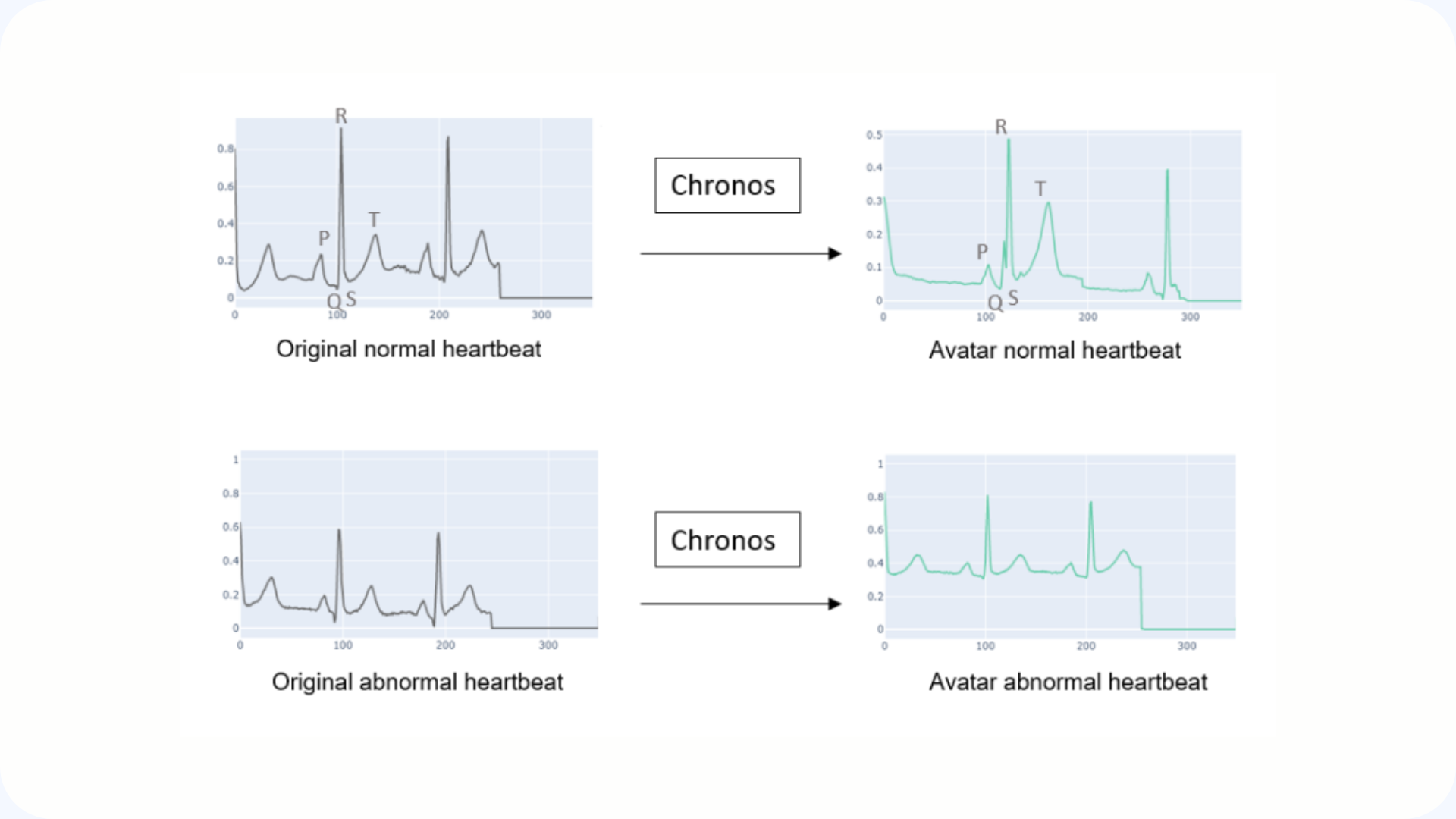
August 25, 2021
Application of a novel Anonymization Method for Electrocardiogram data (Chronos)
Chronos is an anonymization method dedicated to temporal data, tested on ECG signals. It generates synthetic data that is faithful to the original, with only a 3% difference in accuracy on the trained models. An approach that protects individuals while maintaining the scientific quality of data.
March 4, 2025
Leveraging patients’ longitudinal data to improve the Hospital One-year Mortality Risk
This study introduces ELSTM, a neural network that analyzes patients' complete histories to more accurately predict their risk of mortality at one year after admission. To promote research while maintaining confidentiality, the authors have also published a synthetic data set reproducing the real characteristics of patients.
Genetic architecture of Multiple Sclerosis patients in the French national OFSEP-HD cohort
This article presents the genetic analysis of the OFSEP-HD cohort, comprising more than 2,600 patients with multiple sclerosis followed over five years. The study highlights the genetic diversity of patients and the limits of original self-declarations, while proposing the creation of a synthetic and anonymous genetic data set to promote sharing and open research.
June 24, 2025
Privacy-by-design generation of two virtual clinical trials in multiple sclerosis and their release as open datasets
This article discusses the use of the Avatar method to generate synthetic randomized clinical trials using real data from patients with multiple sclerosis. The results show that this approach makes it possible to accurately reproduce clinical analyses while guaranteeing robust confidentiality, even in the face of the most complex inference attacks. Two sets of anonymous and open placebo data have thus been published to demonstrate the potential of the secure sharing of health data.
July 31, 2024
Application of blinded synthetic data: the case of data from the CONSTANCES cohort
This article presents a large-scale scientific validation of the Octopize Avatar method, applied to the CONSTANCES cohort (more than 160,000 individuals). The results show that the synthetic data faithfully reproduce the statistical associations of real data, with minimal differences and a high degree of agreement between the results. This study confirms that avatar data offers a reliable and GDPR-compliant alternative for sharing and exploiting massive data safely.
October 23, 2020
Location of intracranial aneurysms is the main factor associated with rupture in the ICAN population
This article presents the French ICAN project, a national program aimed at better understanding the mechanisms of formation and rupture of intracranial aneurysms. By combining high-throughput genetic analyses, imaging and clinical data, the project seeks to identify new genes and biomarkers that are predictive of aneurysm risk. This work paves the way for the development of new diagnostic and therapeutic tools for better prevention of aneurysms.
April 5, 2023
Pedagogical notebook on the uses of synthetic data
This article presents the collaboration between Octopize and the Health Data Hub around an educational notebook dedicated to the generation and evaluation of synthetic health data. This work compares several approaches to measure both the quality and the level of anonymity of the data produced. The Octopize method is distinguished by its ability to guarantee confidentiality while maintaining scientific reproducibility, regardless of the use case.
October 16, 2024
To be or not to be, when synthetic data meets clinical pharmacology: a study focused on pharmacogenetics
This article compares three synthetic data generation methods — CT-GAN, TVAE, and Avatar — applied to a set of pharmacogenetic data. The results show that Avatar (k = 10) and CT-GAN offer the best balance between data usefulness and privacy, with estimates close to real data. This study highlights the potential of synthetic data for pharmacological research, while identifying ways to optimize small data sets.