

La méthode Avatar, conçue pour l'anonymisation de données tabulaires, peut être détournée, sans modification algorithmique, pour désensibiliser sélectivement une catégorie spécifique au sein d'un jeu de données.
Partager des données sans exposer une catégorie sensible
Prenons un exemple issu d’un contexte de défense. Les armées modernes gèrent des parcs de véhicules terrestres extrêmement diversifiés : véhicules de combat, véhicules de commandement, véhicules légers, véhicules de transports, etc. Pour optimiser la maintenance prédictive, la gestion des stocks et la planification opérationnelle, ces données sont régulièrement partagées entre services, sous-traitants industriels et partenaires.
Or, certaines catégories de véhicules sont intrinsèquement sensibles. C'est le cas par exemple des véhicules transportant du matériel classifié : leurs caractéristiques techniques (masse, autonomie, signatures thermiques et radar) constituent des informations sensibles et identifiantes. Un modèle de machine learning entraîné sur le référentiel complet pourrait facilement identifier ces véhicules, créant une faille de sécurité majeure.
Enjeu : comment partager les données du parc pour les usages logistiques courants, tout en rendant impossible l'identification de la catégorie sensible ?
Méthodologie de désensibilisation et d’évaluation
La méthode Avatar génère, pour chaque individu d'un dataset, un avatar synthétique calculé comme le barycentre pondéré de ses k plus proches voisins dans un espace projeté. Conçue pour l'anonymisation, cette mécanique peut être exploitée autrement.
Le principe : forcer les voisins de chaque véhicule de la classe cible à être exclusivement issus d'autres catégories. L'avatar résultant est alors « tiré » vers les caractéristiques moyennes des véhicules non-sensibles, rendant sa classification beaucoup plus difficile.
Données :
Le jeu de données utilisé est un référentiel technique de véhicules terrestres militaires comprenant 16 caractéristiques mesurées (masse, dimensions, autonomie, signatures…) et 7 catégories de véhicules.
Note: Pour des raisons de confidentialité, les données présentées ici sont issues d'un dataset public (Dry Bean — UCI) dont les variables et classes ont été renommées pour coller à la thématique. Les valeurs numériques sont strictement identiques : les distributions, corrélations et structures statistiques sont celles du dataset réel. Ce choix méthodologique ne diminue en rien la validité de l'analyse, seuls les intitulés sont fictifs, la démonstration statistique reste rigoureuse.
Étapes du protocole d’évaluation :
- Split stratifié 70/30. Le dataset (2 000 lignes) est séparé en entraînement (1 400) et test (600), ce dernier restant inchangé pour les deux modèles.
- Génération du jeu de données désensibilisé: On génère un jeu d’avatars (1400*) à partir du jeu d’entraînement (1 400) avec la particularité que les voisins utilisés lors de la génération ne peuvent pas appartenir à la classe cible à désensibiliser (véhicules transportant du matériel classifié)
- Comparaison : Un algorithme de prédiction XGBoost à isoparamètres est entraîné respectivement sur les données d’entraînement d’origine (1 400) et sur les données d’entraînement désensibilisées (1 400*). Ils sont ensuite évalués et comparés sur le jeu de test inchangé (600) issu des données d’origine.
Résultats
On entraîne un classifieur (XGBoost) avant et après désensibilisation sur les mêmes données de test.
Métriques clés :
- Accuracy globale : La capacité globale du modèle de classification à prédire la classe du véhicule à partir de ses informations reste inchangée 91% → 91%.
- Précision matériel classifié : En revanche, la capacité spécifique du modèle à prédire qu’un véhicule provient de la classe sensible matériel classifié diminue de 30 points avec les données désensibilisées 92% → 62%.
- La performance prédictive spécifique du modèle sur les autres catégories n’est quasiment pas impactée.
Le modèle conserve sa performance globale. Les données restent parfaitement utiles pour la logistique, mais perd significativement sa capacité à identifier les véhicules transportant du matériel classifié.
Analyses complémentaires :
L’analyse des matrices de confusion issues des deux modèles (données d’entraînement brutes, données d’entraînement désensibilisées), permet d'observer la réallocation des prédictions.

La ligne correspondant à la classe cible (matériel classifié) montre une évolution nette. Après désensibilisation, les erreurs de classification augmentent fortement pour cette catégorie, prouvant que le modèle peine à l'isoler en augmentant les confusions entre les classes véhicules de combat et véhicules du génie.
Pour compléter cette analyse, on compare la performance de prédiction spécifique des deux modèles par classe de véhicule (données d’entraînement brutes, données d’entraînement désensibilisées).
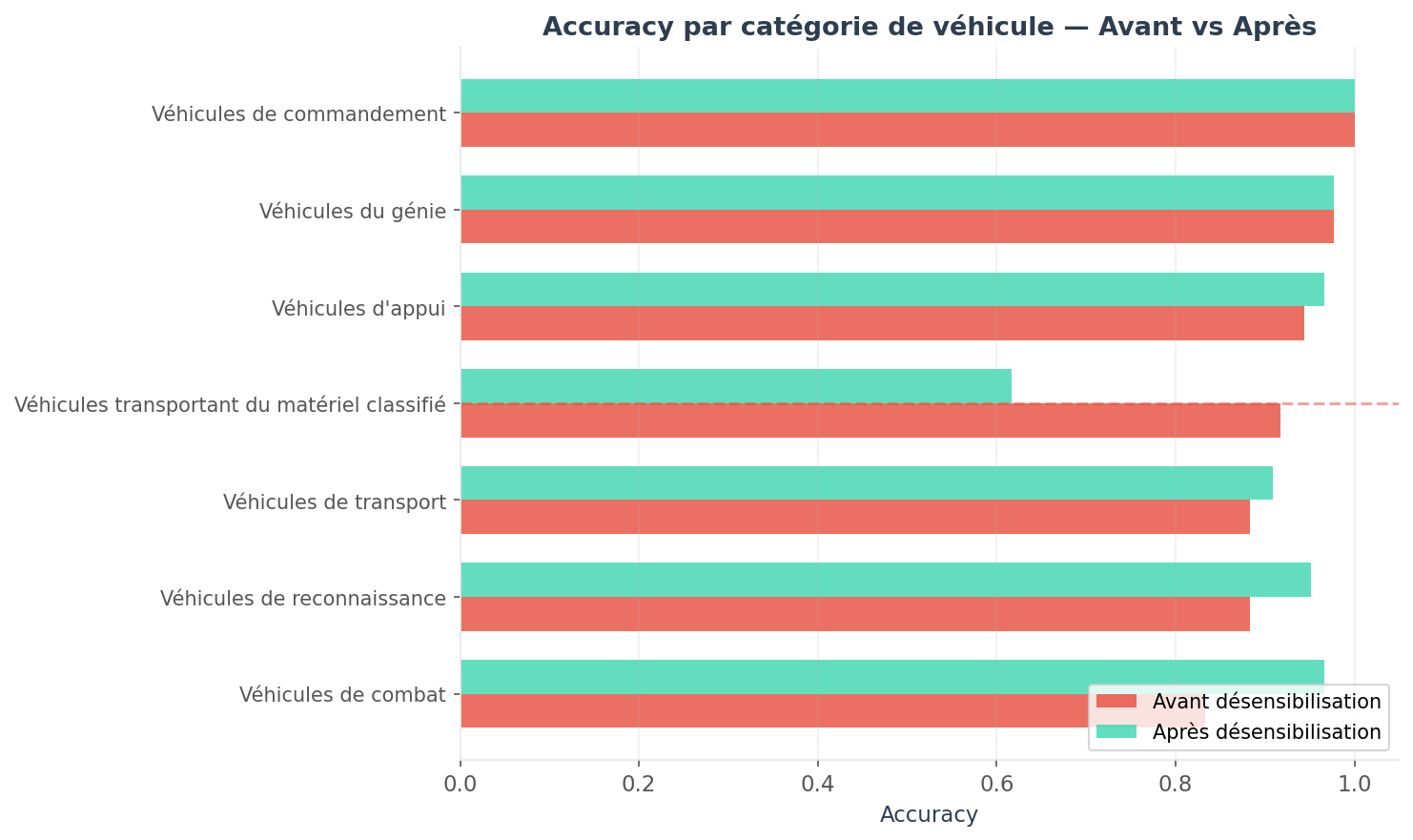
L'impact de la méthode est précisément concentré sur la classe cible. Les autres catégories conservent des performances de prédiction stables et fiables pour les opérations.
Une fois la comparaison des modèles de prédiction effectués, on peut réaliser une analyse plus précise sur les variables de prédiction. L’analyse de l’importance des variables dans la capacité à prédire la classe cible avec les données brutes (non désensibilisées) permet de tracer un profil de la classe cible avant désensibilisation.

Les valeurs SHAP révèlent quelles caractéristiques permettent au modèle d'identifier les véhicules transportant du matériel classifié. Dans notre exemple, la largeur du véhicule est l’information principale permettant au modèle de discriminer une donnée comme provenant de cette classe sensible.
Une fois la variable discriminante principale identifiée, on peut comparer les distributions de la variable de largeur entre les données brutes et désensibilisées.
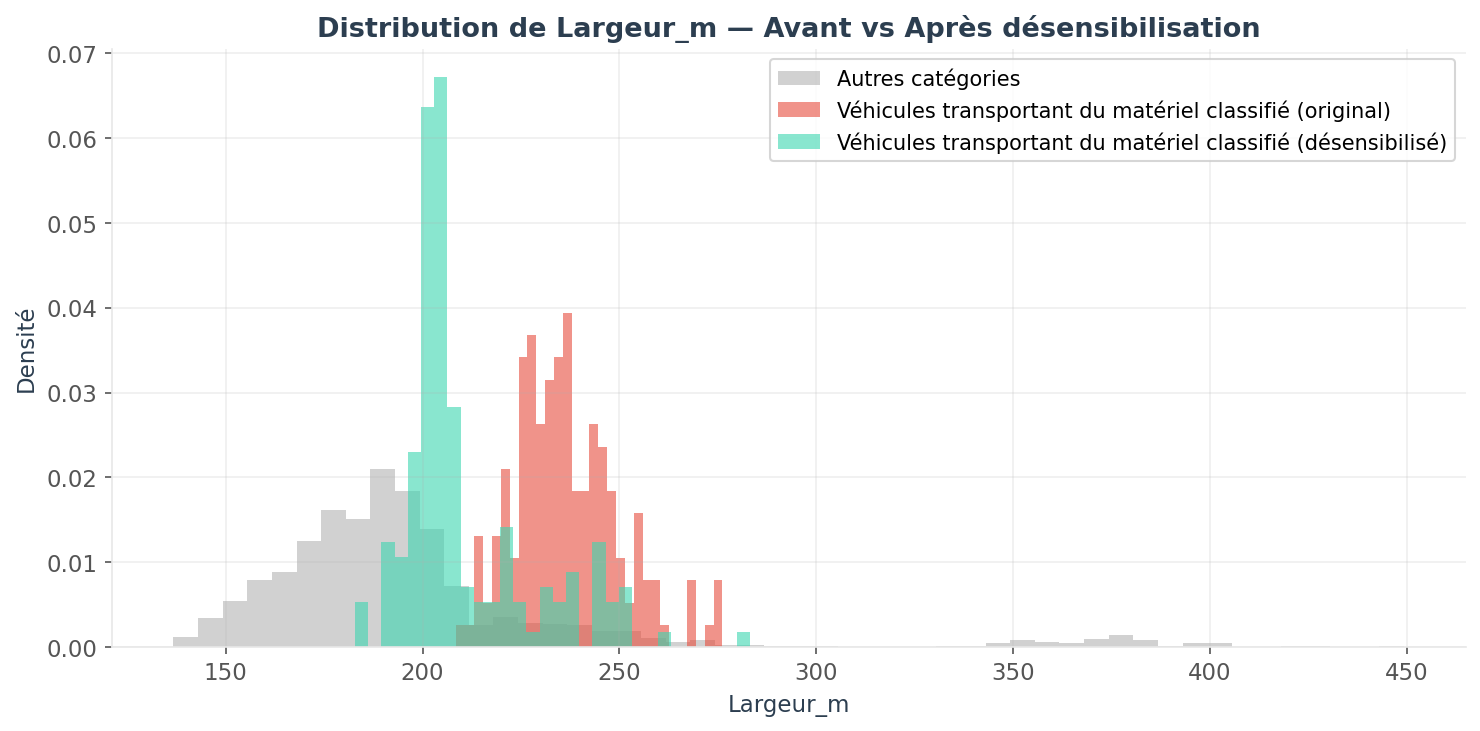
La variable la plus discriminante voit sa distribution pour la classe cible véhicules transportant du matériel classifié se rapprocher considérablement de celle des autres catégories, rendant la distinction purement statistique plus difficile.
Enfin pour compléter l’analyse, on effectue cette fois une analyse multi-modale de la singularité de la classe cible dans un espace de projection.

Une Analyse en Composantes Principales (ACP) non supervisée permet de visualiser ce déplacement dans l'espace des données. Avant l'opération, les véhicules transportant du matériel classifié forment un cluster identifiable et isolé. Après désensibilisation, ces mêmes points se dispersent et se fondent dans les zones de l'espace occupées par les autres catégories de véhicules.
Vérification de robustesse
Un risque potentiel inhérent à ces méthodes : les données désensibilisées pourraient former un nouveau cluster artificiel reconnaissable. L'analyse du voisinage (algorithme KNN avec k=10) montre cependant que la proportion de voisins de même classe passe de ~56% à ~17% — les points se mélangent donc effectivement avec les autres catégories, de manière organique, sans créer de nouveau signal exploitable par un attaquant.
Points d'attention
- Classe cible isolée: L'approche fonctionne d'autant mieux que la classe cible est initialement bien distinguable des autres catégories.
- Corrélations internes: Les corrélations originelles au sein de la classe cible sont mécaniquement altérées par la procédure.
- Paramètre k: L'utilisation d'un k plus grand renforce la désensibilisation mais augmente proportionnellement la perte de structure fine de la donnée.
- Reproductibilité: Le processus reste déterministe (grâce à l'usage d'une seed fixe) et parfaitement auditable par des tiers de confiance.
Conclusion
La méthode Avatar, utilisée ici sans aucune modification de ses algorithmes fondamentaux, permet de réduire significativement la capacité d'un modèle d'apprentissage à identifier une catégorie particulièrement sensible, le tout en préservant intactes les performances globales sur le reste du jeu de données.
En pratique, cela garantit qu'un référentiel logistique critique peut être sereinement partagé entre services gouvernementaux, armées ou partenaires industriels pour des usages courants de MCO (Maintien en Condition Opérationnelle) — tout en assurant qu'un tiers (légitime ou malveillant) ne pourra pas isoler les véhicules transportant du matériel classifié à partir de ces données.
Cette approche novatrice ouvre directement la voie à une fonctionnalité de désensibilisation sélective intégrable nativement dans des plateformes logicielles de confidentialité des données. Elle est transposable à tout contexte (santé, finance, télécoms) où une catégorie très spécifique doit être rendue "furtive" au sein d'un grand jeu de données mutualisé.
Liens
Documentation technique méthode Avatar
Contact



