

Nous avons reproduit l'attaque par chaînage la plus agressive décrite dans la littérature académique et l'avons appliquée à des avatars. Résultat : en conditions réalistes, le risque de ré-identification reste négligeable. Cet article détaille la méthodologie, les résultats, et permet de situer notre propre métrique d'évaluation (Hidden Rate) face à ces standards académiques, le tout contextualisé dans le cadre d'une Analyse d'Impact (AIPD).
L'attaque par chaînage
Le chaînage peut être assimilé au critère d’individualisation défini par le Comité Européen de la Protection des Données (CEPD) pour évaluer l'anonymisation d'un jeu de données, aux côtés de la corrélation et de l'inférence.
Définition. Une attaque par chaînage consiste à relier un enregistrement synthétique (ou un groupe d'enregistrements) à un individu réel. Si cette association est possible, l'anonymisation est compromise.
Dans le contexte des données synthétiques, la question devient : un attaquant peut-il, en exploitant un ou plusieurs jeux de données avatars publiés, reconstituer un lien vers les individus du jeu de données source ?
Nous testons deux variantes:
- V1 (attaque complète) : l'attaquant dispose des données originales ainsi que de t jeux d’avatars. Scénario théorique irréaliste.
- V2 (attaque restreinte) : l'attaquant ne dispose que des avatars publiés ainsi que d'un t jeu d’avatars de seconde génération. Scénario théorique plus réaliste.
Protocole de reproduction
L'attaque repose sur cinq étapes :
- Génération des données:
V1 : on part d’un jeu de données original (AIDS – 2 139 individus, 24 variables mixtes) à partir duquel on produit t = 100 générations d’avatars avec le paramètre k = 5.
V2 : on part d’un jeu de données d’avatars issus des originaux (avatars de première génération) pour produire t = 100 générations d’avatars issus d’avatars (avatars de seconde génération) avec le paramètre k = 5.
- Projection dans un espace latent partagé.
L'ensemble des données (originales et 100 avatars pour V1 – avatars de première génération et 100 avatars de seconde génération pour V2) est projeté dans un sous-espace de dimension réduite via une Analyse Factorielle de Données Mixtes (AFDM).
- Estimation des distributions individuelles.
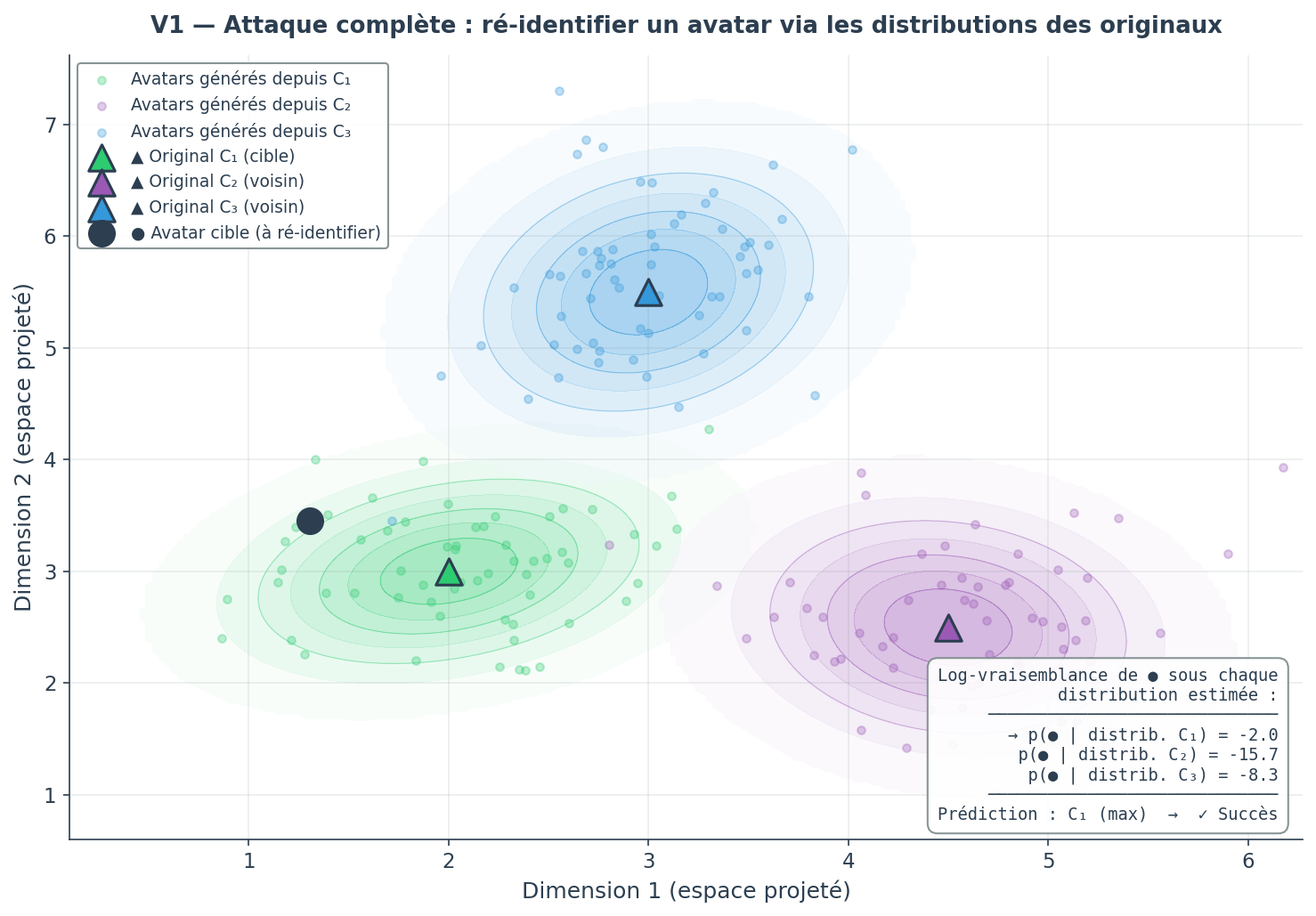
V1 : Pour chaque individu i du jeu d’origine, l'attaquant utilise ses 100 avatars pour estimer une distribution dans l'espace comme une gaussienne multivariée.
V2 : Pour chaque avatar de première génération, l'attaquant utilise ses 100 avatars de seconde génération pour estimer une distribution dans l'espace comme une gaussienne multivariée.
- Restriction aux 50 plus proches voisins.
Pour chaque avatar cible à ré-identifier, l'attaquant restreint les candidats aux 50 individus dont la moyenne estimée est la plus proche(distance euclidienne).
- Assignation par maximum de vraisemblance.
Parmi ces 50 candidats, l'attaquant identifie celui qui maximise la log-vraisemblance sous la distribution estimée. En V1, il évalue chaque avatar cible sous les distributions des originaux voisins. En V2, il évalue chaque avatar de première génération sous sa propre distribution d'avatars de seconde génération.
Le taux de ré-identification final est calculé comme étant la proportion d'avatars correctement assignés à leur individu source. En V1, un succès signifie que l'avatar est attribué au bon original. En V2, un succès signifie que l'avatar de première génération est le point le plus vraisemblable sous sa propre distribution. Autrement dit, il est statistiquement distinguable de ses voisins. Cette singularisation est la condition nécessaire à une ré-identification : si l'attaquant ne parvient pas à distinguer un avatar de ses voisins, il ne peut pas confirmer de lien vers un individu réel, même avec de l'information auxiliaire.

Résultats
Tableau de synthèse

Lecture des résultats
V1 (attaque complète) :
Pour ce jeu de données, Avec k=5 et 100 générations, l'attaquant qui connaît les originaux parvient à ré-identifier 87 % des individus. Ce chiffre peut paraître alarmant pris isolément. Cependant, il repose sur une hypothèse irréaliste : l'attaquant dispose déjà des données personnelles qu'il cherche à ré-identifier. Si l'adversaire connaît déjà les données, la ré-identification n'apporte aucune information supplémentaire.
V2 (attaque restreinte) :
Dans le scénario réaliste, l'attaquant ne parvient à singulariser que 2,6 % des avatars pour k=5, un résultat à peine supérieur au hasard (2 % = 1/50 candidats). Concrètement, pour 97,4 % des avatars, la distribution estimée via avatars d'avatars ne permet pas de les distinguer de leurs voisins : les signatures statistiques se confondent. Si l'attaquant ne peut même pas identifier quel avatar est quel avatar dans le jeu publié, il est a fortiori incapable de remonter à l'individu original.
Comparaison au Hidden Rate :
Le Hidden Rate est une métrique standard d'Octopize pour évaluer la résistance au chaînage : il mesure la proportion d'individus originaux dont le plus proche avatar n'est pas le « sien ». Il s’agit d’une métrique statique et géométrique, calculée sur la base d'une seule génération d'avatars. À l'inverse, V1 et V2 sont des attaques statistiques et dynamiques qui tentent d'exploiter l'accumulation de données à travers plusieurs générations (T=100).
À k=5, 18,5 % des individus sont considérés réidentifiables par chaînage.
Contextualisation
Conformément à l'approche décrite dans notre article sur [l'approche pragmatique de l'anonymisation], il est essentiel de ne pas interpréter des métriques brutes hors contexte.Les mesures montrent que :
- En conditions idéales pour l'attaquant (V1), le risque théorique existe.
- En conditions réalistes (V2), le risque est statistiquement négligeable pour k=5.
- La métrique de chaînage d’Octopize (Hidden Rate) se situe entre ces deux scénarios. C'est un indicateur de compromis prudent : il surestime volontairement le risque par rapport à une attaque réaliste V2 pour garantir une marge de sécurité, tout en restant plus réaliste que le scénario V1.
Pour que l'attaque V1 soit réalisable, un adversaire devrait disposer du jeu original complet, avoir accès à 100 jeux d'avatars indépendants, maîtriser l'estimation statistique avancée, et savoir que ces avatars proviennent du même jeu. Dans la pratique, si un utilisateur publie un seul jeu d'avatars (le cas standard), l'attaque V1 est infaisable. Si, de surcroît, l’attaquant ne dispose d'aucun moyen de générer de nouveaux avatars, l’attaque V2 devient également infaisable.
Impact du nombre de simulation sur la performance de l’attaque
Bien que l’attaque V1 soit irréaliste en pratique, elle soulève une question intéressante. Comment le risque évolue-t-il en fonction du nombre de générations d’avatars disponibles ?
En effet, l’accès à 100 itérations d'avatars d’un jeu d’origine est une hypothèse forte, mais l’accès à 2, 3 voire 10 versions n’est pas improbable, surtout dans un contexte d’utilisation de la méthode pour faire de l’augmentation de données.
Nous avons donc mesuré l'évolution du taux de ré-identification en fonction du facteur d'augmentation, pour k=5 :

V1 (attaque complète) :
progresse rapidement jusqu'à ×20 (~83 %), puis sature autour de 87 %. Au-delà de ×35, le gain marginal est quasi nul — la distribution gaussienne est déjà bien estimée avec une trentaine de points.
V2 (attaque restreinte) :
reste stable entre 1 % et 2,6 % quel que soit le facteur d'augmentation. L'approximation par avatars d'avatars ne converge pas vers les distributions réelles, même avec 50 générations.
Même en publiant un jeu augmenté ×100, le risque en conditions réalistes (V2) reste en zone de risque négligeable (<5 %). L'augmentation de données par avatars reste une pratique sûre du point de vue de la confidentialité.
Conclusion
- La robustesse en conditions réalistes. L'attaque V2 échoue systématiquement. Le processus de génération d'avatars ne conserve pas assez de trace individuelle pour qu'un attaquant sans accès aux originaux puisse reconstituer un lien.
- La cohérence avec le cadre réglementaire. Le RGPD évalue l'anonymisation en termes de « moyens raisonnables ». L'attaque V1 requiert des moyens déraisonnables (accès préalable aux données personnelles) ; l'attaque V2, seule raisonnable, ne produit pas de ré-identification significative.
- La transparence de la démarche. Conformément à notre engagement de transparence, nous publions cette analyse y compris les résultats de V1 — non pas parce qu'ils constituent un risque réel, mais parce qu'ils illustrent la méthodologie et ses limites théoriques.
Liens
- Documentation des métriques de confidentialité
- Article : Approche pragmatique de l'anonymisation (AIPD)
- Article : Comprendre les attaques par inférence d'appartenance
- Contact



