

FastDP is a method for generating synthetic data using differential privacy (DP) mechanisms. It sits alongside Avatar and OpenDP-MST as one of the generation options available on the platform. Each method makes different trade-offs between privacy, data quality, and computation time.
At a high level, FastDP and OpenDP are designed for situations where a formal privacy guarantee is required. Avatar, in contrast, focuses on preserving data fidelity while providing empirical privacy protection. The article aims to understand the trade-off with each approach to choose the right method.
Why FastDP?
Differential privacy principle states that the output of a mechanism should be almost the same whether or not any single individual is included in the dataset. This ensures that no individual can be reliably detected or singled out, regardless of what an attacker already knows.
This property is strong, but it comes at a cost. Injecting noise reduces data quality, the privacy parameter ($\varepsilon$) is not always intuitive to calibrate, and some DP methods can be computationally expensive. We discussed these trade-offs in a [previous article].
Despite these limitations, DP is sometimes required. Regulatory mandates, contractual obligations, or cross-border data sharing may impose the use of formally private methods. For these cases, we provide two DP-based generators alongside Avatar: FastDP and OpenDP MST.
FastDP: a simple parametric approach
FastDP is built on a simple idea: if your data can be approximated by a parametric model, you can make that model differentially private by adding calibrated noise to its parameters.
The process works as follows. First, the original data is projected into a low-dimensional latent space using PCA or FAMD. A parametric model is then fitted in that space (either a single multivariate Gaussian, or a Gaussian Mixture Model (GMM)). Laplace noise is added to the estimated parameters (mean, covariance, and mixture weights) in a way that satisfies $\varepsilon$-differential privacy. Synthetic samples are then generated from the noised model and mapped back to the original feature space.
The only parameter exposed to the user is $\varepsilon$. Lower values mean stronger privacy and more noise; higher values reduce noise but weaken the guarantee.
This approach works well when the data can be reasonably approximated by a Gaussian structure in latent space. It is less effective for highly non-linear distributions, heavy-tailed variables, or complex categorical features. In practice, the main limitation often comes from the model itself rather than the noise: a simple Gaussian cannot capture multimodal or skewed distributions, even with minimal privacy constraints.
OpenDP MST: a marginal-based alternative
OpenDP MST, from the [OpenDP] project, follows a different strategy. Instead of fitting a global parametric model, it builds synthetic data from noisy marginal distributions. It first computes noisy one and two-dimensional frequency tables, then constructs a dependency structure between variables and samples new data from the resulting graphical model.
This approach can better capture relationships in categorical data, but it is significantly more expensive computationally. On a dataset like Adult, for 24,000 rows, generation takes several minutes compared to a few seconds for FastDP or Avatar.
Results on the Adult dataset
We evaluated all three methods on the Adult dataset (~48,800 rows, 15 mixed-type features) using a proper train/test split: synthetic data is generated from the training set only, and all metrics are computed against the held-out test set.
Data quality
The Hellinger distance measures how well the synthetic data preserves each variable's distribution (0 = identical, 1 = completely different). The figure below shows how it evolves as each method's privacy parameter varies.
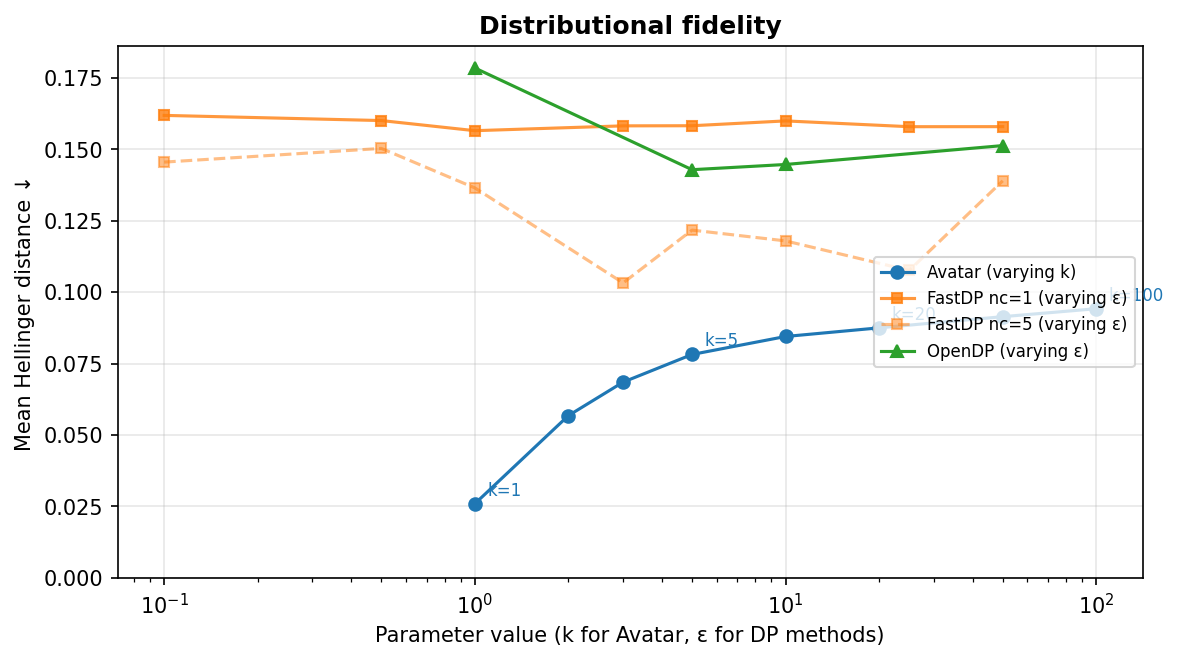
Even at k=100, avatar stays below 0.09. FastDP with a single Gaussian, by contrast, plateaus around 0.155 regardless of $\varepsilon$, even at $\varepsilon = 50$ where almost no noise is injected. The bottleneck is not the noise but the over-simplicity of the model. Using a Gaussian Mixture (nc=5) helps somewhat, bringing the error down to about 0.10 at the best configurations, but the improvement requires high $\varepsilon$ to avoid drowning extra parameters in noise. This high $\varepsilon$ value does not mean that resulting synthetic data is not private, but we cannot rely on the formal privacy guarantee of differential privacy to prove it.
OpenDP shows similar levels of distributional error, improving slowly from 0.16 at $\varepsilon = 1$ to 0.14 at $\varepsilon = 10$.
Privacy: membership inference
We measured resistance to membership inference attacks (MIA), where an attacker tries to determine whether a specific individual was part of the training data. We report the normalized MIA metrics (normalized AUC and normalized protection rate).
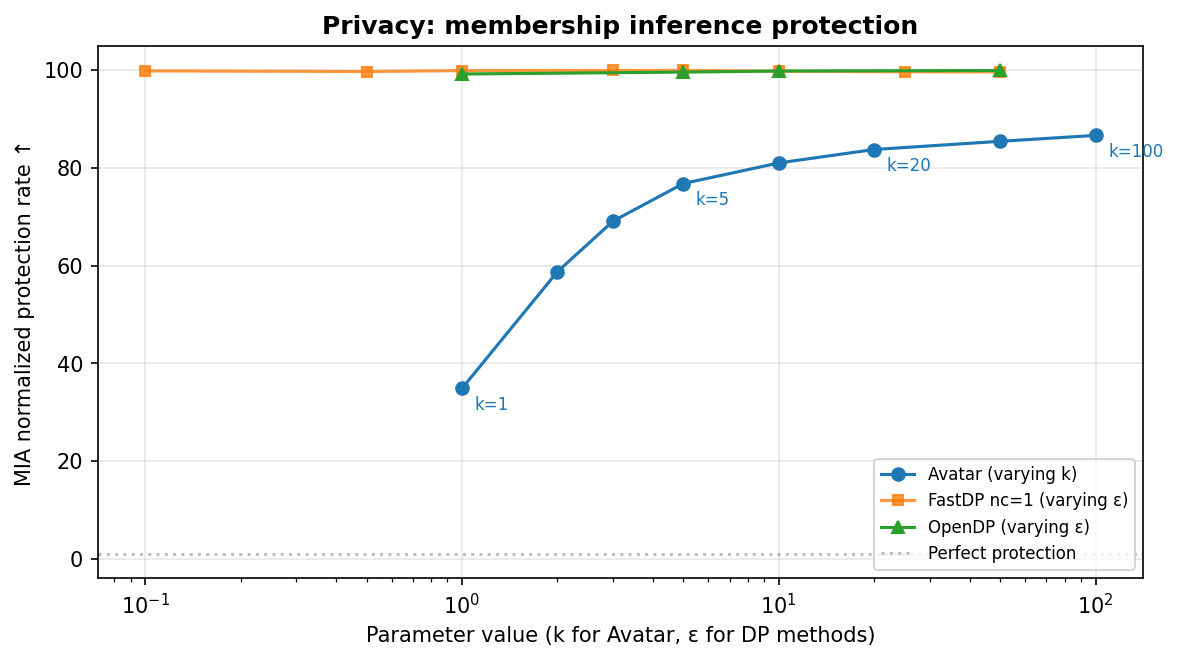
DP methods typically sit near the top of the chart: model simplicity and calibrated noise injection reduces memorization and makes membership detection harder. Avatar's privacy profile is more configuration-dependent: at low k, some membership signal can remain, and protection improves as k increases. The key point is that all methods can reach privacy protection in practice, but they do so with different privacy-utility trade-offs.
The trade-off
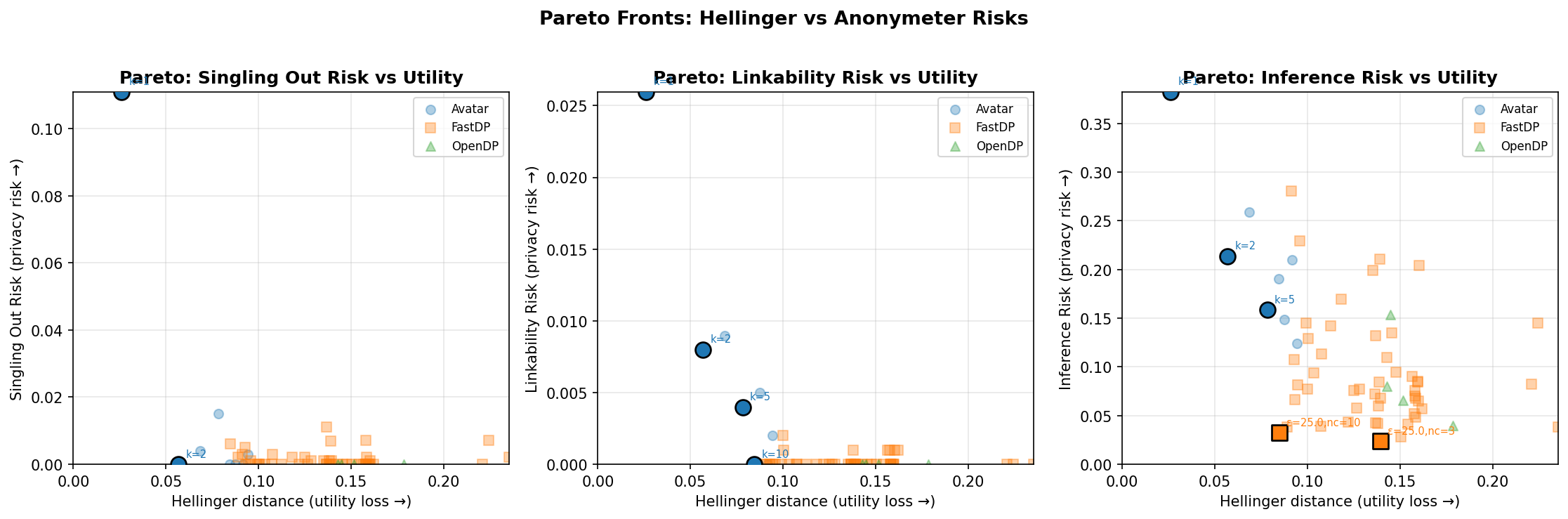
The Pareto chart below shows privacy risk against utility loss for membership inference. Each point is one configuration; highlighted points are Pareto-optimal. Lower is better on both axes, so the ideal corner is bottom-left.

Avatar configurations generally occupy the left side of the chart (better distributional fidelity), while DP methods tend to remain close to zero privacy risk on this MIA view.
Anonymeter attack simulations
We also ran Anonymeter's simulations against the three GDPR re-identification criteria: singling out, linkability, and inference. Anonymeter evaluates the advantage of an attacker seeing the synthetic dataset over a control a dataset. The figure below shows one Pareto subplot per risk. Lower is better on both axes, and highlighted points are Pareto-optimal configurations.
All three methods show low risk levels overall for singling out and linkability. The inference subplot is more spread out, with a few higher-risk configurations at low Avatar k or intermediate FastDP settings. These results show that, under these configurations, synthetic data do not reach a perfectly independent population from the training set, but the privacy risks can remain very moderate.
When to use each method?
Avatar is better suited for use cases where data utility is preferred: machine learning, statistical analysis, data augmentation. It preserves complex structures more effectively and scales well even on small datasets, where DP noise tends to dominate. Its privacy protection is empirical rather than formally bounded.
FastDP is a good choice when a strict privacy constraints are required, yet preserving the overall utility of the data with an efficient algorithm. It is fast, simple to configure, and exposes a single privacy parameter.
OpenDP MST is relevant when a formal differential privacy guarantee is required, but it comes with significantly higher computation cost and reduced data utility.
Summary
FastDP and OpenDP provide differential privacy mechanisms to generate synthetic data at the cost of reduced data quality. Avatar provides better data fidelity with empirical privacy protection, but without differential privacy guarantees. The choice depends on the constraints of the use case: when compliance requires a formal guarantee, FastDP and OpenDP methods are the right tool; when the priority is to preserve the structure and usefulness of the data, Avatar is typically the better option.
Links :
- Why Avatar doesn't use Differential Privacy: [octopize.io — article DP]
- MIA metric documentation: [docs.octopize.io — MIA]
- Technical documentation: [docs.octopize.io]
- Contact: [contact@octopize.io]



