

FastDP est une méthode de génération de données synthétiques utilisant des mécanismes de confidentialité différentielle (differential privacy, DP). Elle se place aux côtés d'Avatar et d'OpenDP-MST comme l'une des options de génération disponibles sur la plateforme. Chaque méthode implique des compromis différents entre confidentialité, qualité des données et temps de calcul.
FastDP et OpenDP sont conçus pour les situations où une garantie formelle de confidentialité est requise. Avatar se concentre sur la préservation de la fidélité des données tout en apportant une protection empirique de la confidentialité. Cet article vise à explorer le compromis de chaque approche afin de choisir la bonne méthode pour vos cas d'usage.
Pourquoi FastDP ?
Le principe de la confidentialité différentielle indique que la sortie d'un mécanisme doit être quasiment invariant, qu'un individu donné soit présent ou non dans le jeu de données. Cela garantit qu'aucun individu ne peut être détecté de manière fiable ni isolé, quel que soit l'information auxiliaire qu'un attaquant dispose.
Cette propriété est forte et désirable, mais elle a un coût. L'injection de bruit réduit la qualité des données, le paramètre de confidentialité ($\varepsilon$) n'est pas toujours intuitif à calibrer, et certaines méthodes DP peuvent être coûteuses en calcul. Nous avons discuté de ces compromis dans un [article précédent].
Malgré ces limites, la DP est parfois requise. Des contraintes réglementaires, contractuelles ou de partage de données peuvent imposer l'usage de ces méthodes. Pour ces cas, nous proposons deux générateurs basés sur la DP en plus d'avatar : FastDP et OpenDP MST.
FastDP : une approche paramétrique simple
FastDP repose sur une idée simple : si vos données peuvent être approximées par un modèle paramétrique, vous pouvez rendre ce modèle différentiellement privé en ajoutant un bruit calibré à ses paramètres.
Le processus fonctionne comme suit. D'abord, les données originales sont projetées dans un espace latent de faible dimension via PCA ou FAMD. Un modèle paramétrique est ensuite ajusté dans cet espace (soit une gaussienne multivariée unique, soit un mélange de gaussiennes (Gaussian mixture models, GMM)). Un bruit de Laplace est ajouté aux paramètres estimés (moyenne, covariance et poids du mélange) d'une manière qui satisfait la confidentialité différentielle en $\varepsilon$. Des échantillons synthétiques sont ensuite générés à partir du modèle bruité puis reprojetés dans l'espace des variables d'origine.
Le seul paramètre exposé à l'utilisateur est $\varepsilon$. Des valeurs plus faibles signifient une confidentialité plus forte et plus de bruit ; des valeurs plus élevées réduisent le bruit mais affaiblissent la garantie.
Cette approche fonctionne bien lorsque les données peuvent être raisonnablement approximées par une structure gaussienne dans l'espace latent. Elle est moins efficace pour des distributions très non linéaires, des variables à queues lourdes ou des variables catégorielles complexes. En pratique, la principale limite vient souvent du modèle lui-même plutôt que du bruit : une gaussienne simple ne peut pas capturer des distributions multimodales ou asymétriques, même avec des contraintes de confidentialité minimales.
OpenDP MST : une alternative basée sur les marginales
OpenDP MST, issu du projet [OpenDP], suit une stratégie différente. Au lieu d'ajuster un modèle paramétrique global, il construit des données synthétiques à partir de distributions marginales bruitées. Il calcule d'abord des tables de fréquences bruitées en une et deux dimensions, puis construit une structure de dépendance entre variables et échantillonne de nouvelles données depuis le modèle graphique obtenu.
Cette approche peut mieux capturer les relations dans les données catégorielles, mais elle est nettement plus coûteuse en calcul. Sur un jeu de données comme Adult, pour 24 000 lignes, la génération prend plusieurs minutes contre quelques secondes pour FastDP ou Avatar.
Résultats sur le jeu de données Adult
Nous avons évalué les trois méthodes sur le jeu de données Adult (~48 800 lignes, 15 variables mixtes) avec une séparation train/test correcte : les données synthétiques sont générées uniquement à partir du train, et toutes les métriques sont calculées sur le test mis de côté.
Qualité des données
La distance de Hellinger mesure à quel point les données synthétiques préservent la distribution de chaque variable (0 = identique, 1 = complètement différente). La figure ci-dessous montre son évolution lorsque le paramètre de confidentialité de chaque méthode varie.
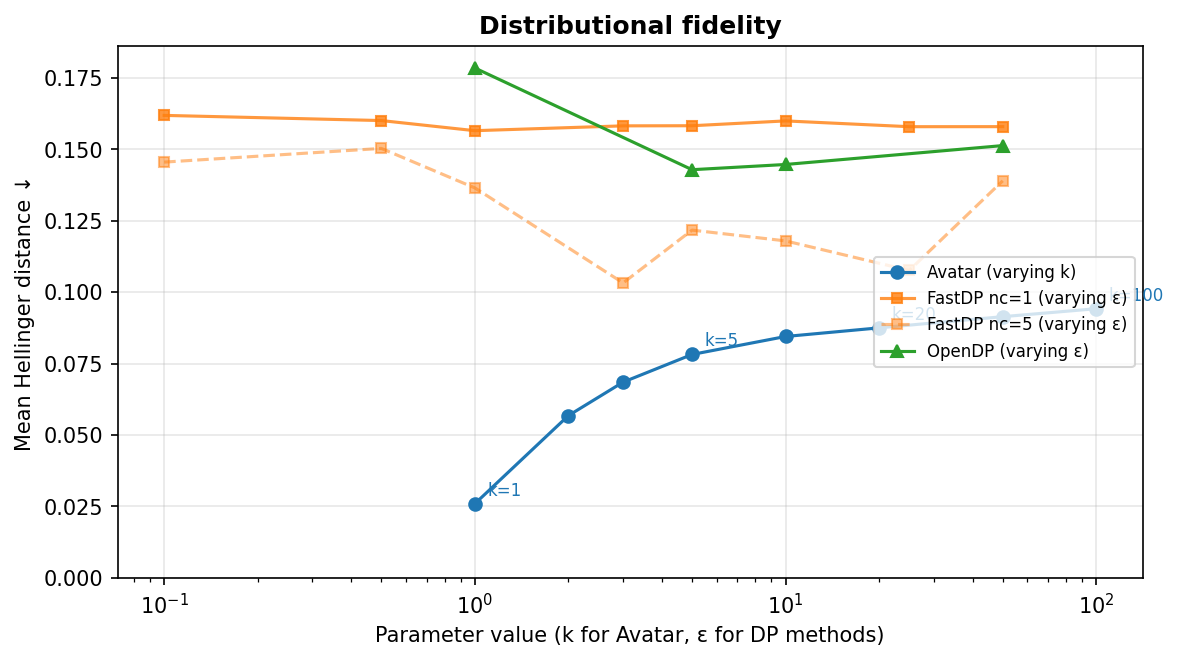
Même à k=100, Avatar reste sous 0.09. FastDP avec une gaussienne unique, en revanche, plafonne autour de 0.155 quel que soit $\varepsilon$, même à $\varepsilon = 50$ où presque aucun bruit n'est injecté. Le goulot d'étranglement n'est pas le bruit mais la simplicité excessive du modèle. L'utilisation d'un mélange gaussien (nc=5) aide partiellement, en ramenant l'erreur vers 0.10 dans les meilleures configurations, mais l'amélioration nécessite un $\varepsilon$ élevé pour éviter que le bruit ne noie les paramètres supplémentaires. Une valeur élevée de $\varepsilon$ ne signifie pas que les données synthétiques ne sont pas privées, mais on ne peut plus s'appuyer sur la garantie formelle de la confidentialité différentielle pour le démontrer.
OpenDP montre des niveaux d'erreur de distribution similaires, en s'améliorant lentement de 0.16 à $\varepsilon = 1$ à 0.14 à $\varepsilon = 10$.
Confidentialité : attaque par inférence d'appartenance
Nous avons mesuré la résistance aux attaques par inférence d'appartenance (MIA), où un attaquant tente de déterminer si un individu spécifique faisait partie des données d'entraînement. Nous reportons les métriques MIA normalisées (AUC normalisée et taux de protection normalisé).
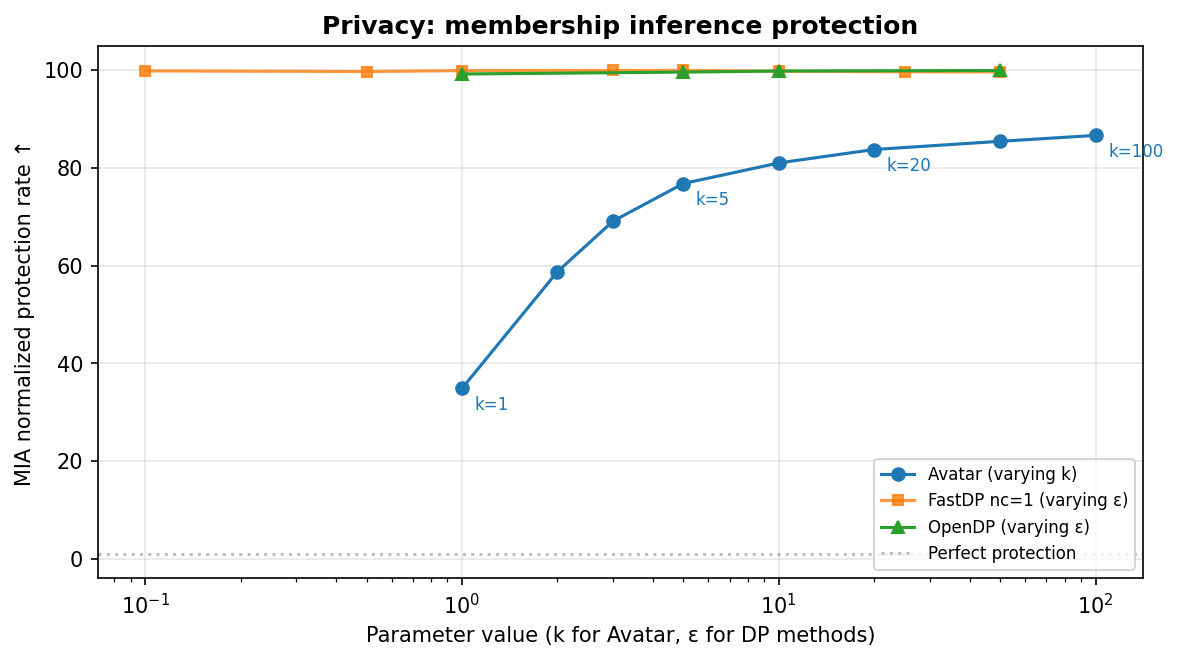
Les méthodes DP se situent typiquement en haut du graphique : la simplicité des modèles et l'injection calibrée de bruit réduisent la mémorisation et rendent la détection d'appartenance plus difficile. Le profil de confidentialité d'Avatar dépend davantage de la configuration : à faible k, un signal d'appartenance peut subsister, et la protection s'améliore quand k augmente. Le point clé est que toutes les méthodes peuvent atteindre une protection de confidentialité en pratique, mais avec des compromis confidentialité-utilité différents.
Le compromis
Le graphique de Pareto ci-dessous montre le risque de confidentialité face à la perte d'utilité pour l'attaque MIA. Chaque point correspond à une configuration ; les points highlights sont Pareto-optimaux. Plus bas est meilleur sur les deux axes, donc le coin idéal est en bas à gauche.

Les configurations Avatar occupent généralement la partie gauche du graphique (meilleure fidélité distributionnelle), tandis que les méthodes DP tendent à rester proches d'un risque de confidentialité nul sur cette vue MIA.
Simulations d'attaques Anonymeter
Nous avons également lancé les simulations d'Anonymeter sur les trois critères de ré-identification du RGPD : individualisation (singling out), liaison (linkability) et inférence. Anonymeter évalue l'avantage d'un attaquant qui voit le jeu de données synthétiques par rapport à un jeu de contrôle. La figure ci-dessous montre un sous-graphe de Pareto par risque. Plus bas est meilleur sur les deux axes, et les points highlights sont les configurations Pareto-optimales.
Les trois méthodes montrent globalement de faibles niveaux de risque pour l'individualisation et la liaison. Le sous-graphe d'inférence est plus étalé, avec quelques configurations à risque plus élevé pour des k faibles d'Avatar ou des réglages intermédiaires de FastDP. Ces résultats montrent que, sous ces configurations, les données synthétiques n'atteignent pas une population parfaitement indépendante du jeu d'entraînement, mais que les risques de confidentialité peuvent rester très modérés.

Quand utiliser chaque méthode ?
Avatar est mieux adapté aux cas d'usage où l'utilité des données est prioritaire : apprentissage automatique, analyse statistique, augmentation de données. Il préserve plus efficacement les structures complexes et passe bien à l'échelle, y compris sur de petits jeux de données, où le bruit DP a tendance à dominer. Sa protection de confidentialité est empirique plutôt que formellement bornée.
FastDP est un bon choix lorsque des contraintes strictes de confidentialité sont requises, tout en préservant l'utilité globale des données avec un algorithme efficace. Il est rapide, simple à configurer, et n'expose qu'un seul paramètre de confidentialité.
OpenDP MST est pertinent lorsqu'une garantie formelle de confidentialité différentielle est requise, mais il implique un coût de calcul nettement plus élevé et une utilité des données réduite.
Résumé
FastDP et OpenDP fournissent des mécanismes de confidentialité différentielle pour générer des données synthétiques au prix d'une baisse de qualité des données. Avatar fournit une meilleure fidélité des données avec une protection empirique de la confidentialité, mais sans garantie de confidentialité différentielle. Le choix dépend des contraintes du cas d'usage : lorsque la conformité exige une garantie formelle, les méthodes FastDP et OpenDP sont le bon outil ; lorsque la priorité est de préserver la structure et l'utilité des données, Avatar est en général la meilleure option.
Liens :
- Pourquoi Avatar n'utilise pas la confidentialité différentielle : [octopize.io — article DP]
- Documentation de la métrique MIA : [docs.octopize.io — MIA]
- Documentation technique : [docs.octopize.io]
- Contact : [contact@octopize.io]



